Unsere neuen Ceph HA-vServer Produkte sind nun schon seit einiger Zeit auf unserer Website verfügbar und die ersten Kundenprojekte konnten bereits erfolgreich in Betrieb genommen werden. Ebenfalls konnten wir, bereits erste Kundenwünsche als neue Funktionen in unser vServer Management integrieren.
Das durchweg positive Kunden-Feedback nehmen wir zum Anlass, um euch einen Blick hinter die Kulissen unserer neuen Ceph HA vServer zu liefern – denn Transparenz steht für uns an oberster Stelle.
Technischer Aufbau
Um eine fachlich fundierte Einschätzung der von unserem Setup gebotenen Resilienz zu ermöglichen, gehen wir im Folgenden detailliert auf unseren technischen Aufbau ein.
Cluster Hostsysteme

Unsere CEPH-HA vServer werden auf einem hochverfügbaren Proxmox-Cluster, bestehend aus mindestens drei Hostsystemen, betrieben. Jedes dieser Hostsysteme verwendet dabei ausschließlich hochwertige Serverkomponenten:
- AMD EPYC CPUs
- SuperMicro Mainboards
- Enterprise NVMe SSDs (Hot-Plug fähig)
- redundante PSUs (Netzteile) – gespeist über unterschiedlichen Stromfeeds und USV Systeme
- ECC Registered Arbeitsspeicher
- zwei-fach redundante NICs (Netzwerkkarten)
Alle Hostsysteme sind Teil eines verteilten Ceph-Filesystems, welches als Storage-Backend für die Disks der virtuellen Maschinen dient. Durch die bei Ceph übliche Redundanz von drei liegt somit jede vServer-Disk effektiv in drei separaten Kopien innerhalb des Clusters vor.
Aus Performancegründen sind die Hostsysteme eines Clusters nicht geografisch verteilt, sondern befinden sich innerhalb desselben Racks. Die Verbindung zwischen den Hostsystemen erfolgt dabei über 2×100 Gigabit/s Netzwerkports, welche mittels LACP in eine LAG gebündelt werden. Somit wird immer eine hohe IO-Bandbreite für eine schnelle Datensynchronisation / Datenbereitstellung innerhalb der virtuellen Maschinen gewährleistet.
Unser vServer Panel stellt zudem sicher, dass jederzeit ausreichend freie Ressourcen im Cluster verfügbar sind, um im Bedarfsfall die VMs eines potenziell ausgefallenen Hostsystems auf die verbleibenden Hostsysteme zu verteilen und dort neu zu starten.
Betriebsumgebung – Standort
Die HA-Cluster befinden sich an unserem Rechenzentrumsstandort FRA1 (NTT). Bei der Wahl unserer Rechenzentrumsstandorte achten wir stets auf höchste Qualitäts- und Zertifizierungsstandards. So verfügt auch der Rechenzentrumscampus FRA1–NTT über eine hochverfügbare, autarke Notstromversorgung in jedem einzelnen Gebäude – bestehend aus Dieselgeneratoren sowie batteriegestützten USV-Anlagen unterschiedlicher Hersteller pro Stromfeed, wodurch sich auch längere Stromausfälle zuverlässig überbrücken lassen.
Die zwei PDUs in jedem Rack werden von zwei physikalisch getrennten Stromfeeds versorgt. Alle für den Betrieb des Clusters benötigten Server- und Netzwerkkomponenten verfügen über zwei redundante Netzteile, die jeweils von einem der beiden Stromfeeds gespeist werden. Durch dieses Setup – und die zweifache Redundanz des Netzwerkequipments – wird das Ausfallrisiko aufgrund einer unterbrochenen Stromversorgung auf ein Minimum reduziert.
Neben einer redundanten Stromversorgung und einem redundanten Netzwerkaufbau ist selbstverständlich auch eine konstante Umgebungstemperatur beim Betrieb von Serveranlagen entscheidend. Die NTT-Rechenzentren verfügen hierzu über redundante Klimaspangen, die sich an beiden Gebäudeseiten gegenüberliegen. Im Fehlerfall kann eine einzelne Klimaspange den gesamten Rechenzentrumsbetrieb aufrechterhalten und so eine Überhitzung der Serversysteme sowie ein daraus resultierendes Notabschalten verhindern.
Bereits seit über 4 Jahren betreibt IP-Projects bei der NTT Serversysteme. Bislang kam es zu keinerlei technischen Ausfällen im Rechenzentrumsbetrieb.
Netzwerk

Für die Internetanbindung der vServer eines Ceph-Cluster-Knotens verfügen die Hostsysteme über mindestens 2×10 Gbit/s LACP-Uplink zum IP-Projects Netzwerk. Diese Netzwerkanbindung steht zusätzlich zu den 2×100 Gbit/s Netzwerkverbindungen zwischen den Clusterknoten zur Verfügung.
Jedes unserer Racks ist dafür mit einem zweifach redundanten Switch-Stack ausgestattet. Die redundanten Netzwerkports der Hostsysteme werden stets auf beide Switches verteilt, um im Wartungs- oder Fehlerfall eines Switches die unterbrechungsfreie Verfügbarkeit bei reduzierter Bandbreite sicherzustellen. Fällt einer der beiden Switches aus, bleibt das Cluster weiterhin erreichbar – jedoch mit temporär halbierter Bandbreite.
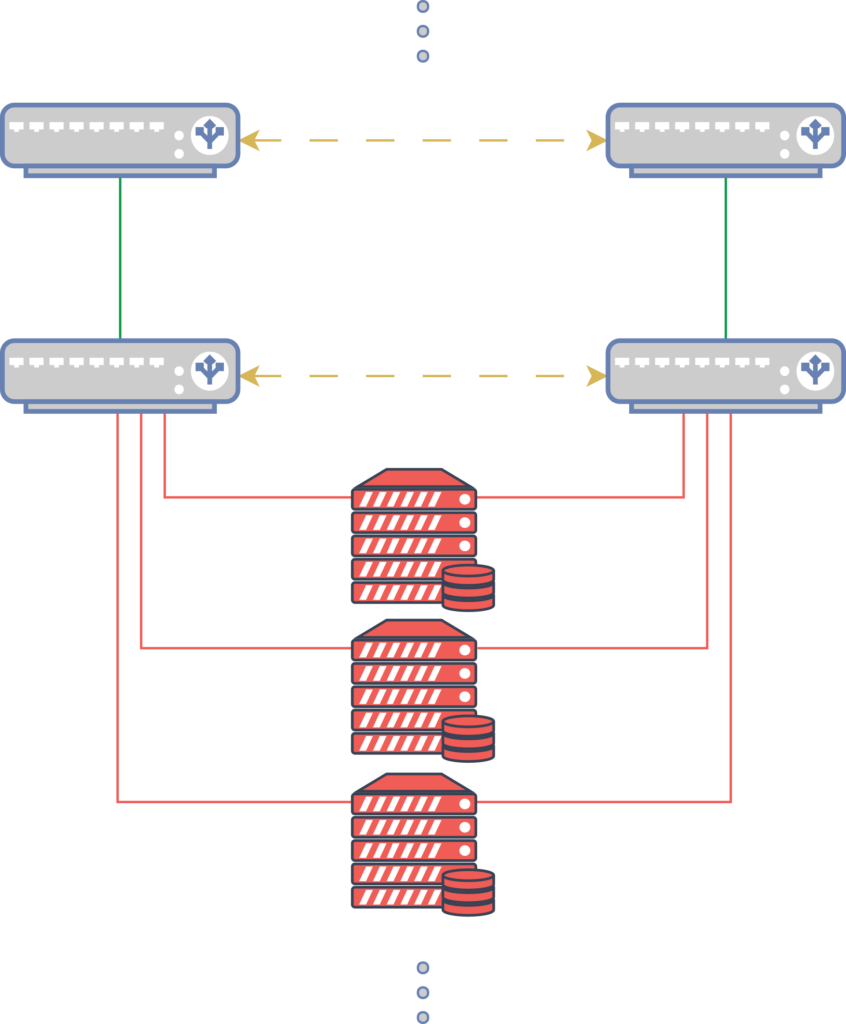
Netzwerksetup (Uplink) der HA vServer Cluster
Dieses Netzwerkdesign zieht sich durch das gesamte IP-Projects Netzwerk bis hin zu den Internet-Uplinks zu den Netzwerk-Carriern. Man spricht dabei von einem „wartungstoleranten“ Netzwerkaufbau.
Um zusätzlich Ausfälle einzelner Switches zu vermeiden, verfügt jeder Switch über zweifach redundante, Hot-Plug-fähige Netzteile, die über beide Stromfeeds des Racks versorgt werden. Auch die Lüfter der Switches sind Hot-Plug-fähig.
Selbst bei einem Defekt eines Netzteils oder Lüfters kann somit ein unterbrechungsfreier Austausch der defekten Komponente im laufenden Betrieb erfolgen. Ein zentrales Monitoring überwacht dabei permanent den Status der Switches – inklusive deren Hardwarekomponenten.
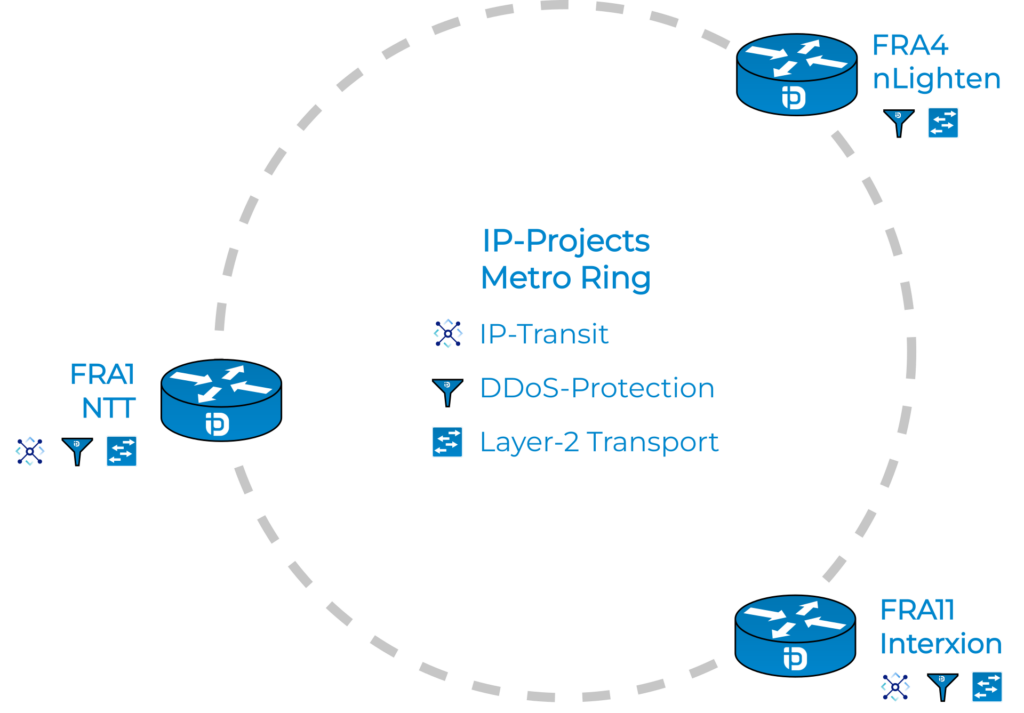
Die redundante Ring-Netzwerkarchitektur zwischen unseren Standorten
Alle Rechenzentrumsstandorte sind über wegeredundante Darkfiber innerhalb eines hochverfügbaren Netzwerkrings miteinander verbunden. Bei einer Darkfiber handelt es sich um unbeleuchtete Glasfaserverbindungen, deren Betrieb – also die „Beleuchtung“ – vollständig in unserer Verantwortung liegt. Es gibt daher kein aktives Netzwerkequipment auf Anbieterseite und daher auch keine Kapazitätseinschränkungen oder Bandbreitenlimitierungen.
Unsere Darkfiber Strecken verfügen dabei über passive Multiplexer. Ein Multiplexer teilt dabei mithilfe eines Prismas die Verbindungen auf einer Darkfiber in verschiedene Wellenlängen (Farben) auf, was es ermöglicht, die Kapazitäten phasenweise auszubauen. Dank des Einsatzes von Multiplexern ist es uns möglich, mit gängigen Standards eine Erweiterung der Kapazitäten auf bis zu 1,6 Tbit/s pro einzelner Darkfiber-Verbindung durchzuführen. Wir erweitern daher nach Bedarf unsere Strecken um weitere Glasfaser-Transceiver, sollte eine Kapazität von 50 % pro Darkfiber-Verbindung erreicht werden. Eine Erweiterung bei 50 % Kapazität ist immer notwendig um einer Überlastung im Fehlerfall einer einzelnen redundanten Strecke entgegenzuwirken.
Die jeweiligen Router-Endpunkte werden zudem mithilfe des OSPF-Protokolls untereinander verknüpft. Dieses sorgt selbst beim Komplettausfall einer wegeredundanten Verbindung dafür, dass der Traffic einen alternativen Weg über einen unserer anderen Standorte findet – sodass ein Ausfall nur wenige Datenpakete betrifft, bis die Routen durch die Router neu gelernt wurden.
High Availability
Im Folgenden wollen wir auf die Charakteristiken und abgedeckten Ausfallszenarien eingehen, welche unser oben erläutertes Setup abdeckt.
Charakteristika in Kürze
Unser High-Availability-Konzept schützt vor den meisten hardwarebedingten Ausfällen:
- Hochwertige Serverkomponenten sorgen für eine hohe Verfügbarkeit und ein minimales Fehlerpotential
- Redundante Stromfeeds und Netzteile im ganzen Stack gewährleisten eine stabile Stromversorgung der Server und des Netzwerkequipments
- CEPH schützt die Daten beim Ausfall einzelner Disks (NVMe-SSDs) und gesamter Clusterknoten
- Ausfälle einzelner Hostsysteme führen nicht zum Ausfall des gesamten Clusters
- Netzwerkredundanzen stellen sicher, dass eine fehlerhafte Netzwerkkarte oder ein defekter Switch nur eine Bandbreitenreduktion, aber keinen Komplettausfall verursacht
- Redundante Uplinks an jedem Standort gewährleisten eine hohe Ausfallsicherheit
- Redundante Darkfiber-Verbindungen zu anderen Standorten ermöglichen ein effektives Fallback bei einem Ausfall aller Uplinks an einem Standort
- Notstromversorgung schützt vor kurz- und mittelfristigen Stromausfällen
- Redundante Klimatisierung schützt vor Abschaltung der Server durch Überhitzung
- Löschanlage zum Schutz vor Bränden
Von unserem Setup nicht abgedeckt sind Szenarien, bei denen das gesamte Cluster ausfällt, wie beispielsweise Totalverlust durch einen Brand oder ein vollständiger Stromausfall über alle Stromfeeds hinweg.
Um unsere Kunden dennoch vor einem Totalverlust der Daten zu schützen, beinhalten unsere HA vServer Produkte ein kostenloses tägliches Backup. Die täglichen Datensicherungen werden dabei auf Proxmox Backup Servern (PBS) gespeichert, die sich in einem komplett autarken Rechenzentrum – unabhängig der Hostsysteme des Clusters – befinden. Sollte ein tägliches Backup nicht ausreichend sein, gibt es die Option, die Vorhaltedauer der Backups auf 7 Tage zu erweitern, und/oder zusätzlich weitere vServer Backup Features zu nutzen.
Failover Szenario
Sollte es dennoch zu einem Ausfall eines einzelnen Cluster Hostsystems kommen, verhält sich das hochverfügbare Cluster wie folgt:
- Der Clusterservice überwacht permanent den Status der Clusterteilnehmer über ein eigenes internes Monitoring. Sollte einer der Knoten eine Störung aufweisen, ist der Clusterservice auf diesem Knoten nicht mehr erreichbar.
- Nach einer Wartezeit von ca. 60 Sekunden deklariert der Clusterservice den Knoten als offline und prüft, welche virtuellen Maschinen gestartet waren. Der Status einer virtuellen Maschine wird über „High Availability Groups“ definiert. Dabei wird sichergestellt, dass keine bewusst gestoppten VMs im Fehlerfall wieder gestartet werden.
- Der Clusterservice beginnt, nach Prüfung der High Availability Groups, die virtuellen Maschinen auf die verbleibenden Server im Cluster nach Ressourcenbedarf zu verteilen und diese wieder zu starten. Durch den Ausfall des Hostsystems gehen die Arbeitsspeicherinhalte verloren, da diese nicht hochverfügbar abgebildet werden.
- Die virtuellen Maschinen stehen jetzt wieder zur Verfügung. Dieser Vorgang dauert daher maximal 60-120 Sekunden bis die VMs wieder starten. Dank des Ceph-Clusters gibt es durch den Ausfall eines einzelnen Hostsystems höchstens minimalen Datenverlust.
- Sobald der Fehler beim ausgefallenen Server gefunden und behoben wurde, verbindet sich dieser wieder mit dem Cluster und synchronisiert sich im Ceph-Cluster neu, sodass dieser wieder einen aktuellen Datenstand aufweist. Die zuvor umverteilten virtuellen Maschinen werden anschließend wieder auf diesen Hypervisor live (inklusive Betriebszustand bzw. Arbeitsspeicherinhalt) zurückgespielt, um die optimale Ressourcenverteilung wiederherzustellen.
Cluster Wartungstoleranz
Dank des Ceph Clusters ist es zudem möglich, im Zuge von Softwareupdates oder Serverseitigen Wartungen die virtuellen Maschinen live auf andere Clusterknoten innerhalb von Sekunden zu verschieben. Selbst bei einem größeren Softwareupdate der Hostsysteme, oder des Ceph Clusters ist daher mit keiner Ausfallzeit für unsere Kunden zu rechnen.
Noch Fragen?
Wenn Ihnen unser Beitrag zu unseren Ceph Cluster vServer Angeboten gefallen hat, oder Sie weitere Fragen zu unseren Angeboten haben, stehen Ihnen unsere Mitarbeiter gerne mit Rat und Tat zur Seite. Treten Sie dafür gerne mit uns in Kontakt.